續上一篇機器學習 挑戰 - Day 1,
我們今天要來詳細研究一下如何套用machine learning module 來預測BTC的價格。
首先想要研究的是Auto-Regressive Integrated Moving Average (ARIMA)。
Auto-Regressive Integrated Moving Average (ARIMA)
用於時間序列分析預測的一般統計模型。
由3個組成部分組成:AR + I + MA(p,d,q)
例如:
AR:ARIMA(p,0,0)= AR(p)
MA:ARIMA(0,0,q)= MA(q)
ARIMA:ARIMA(p,0,q)
首先,又知道要用什麼p,d,q的指數,我們得確認一下數據是否平穩。
**Step1 : **我們可以先觀察一下ACF以及PACF的趨勢。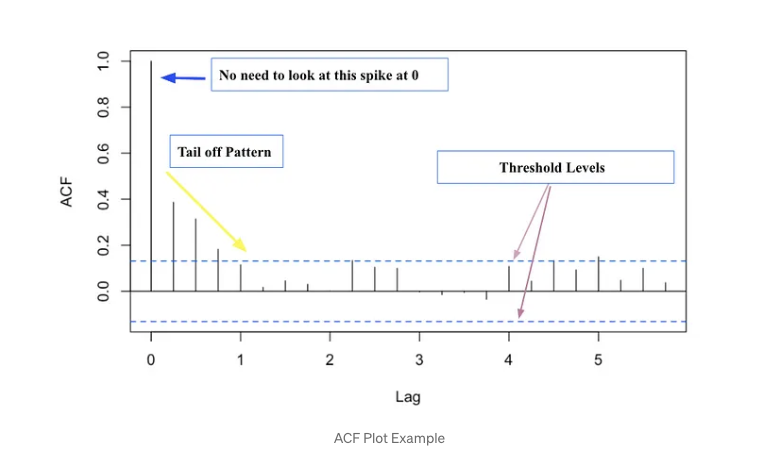
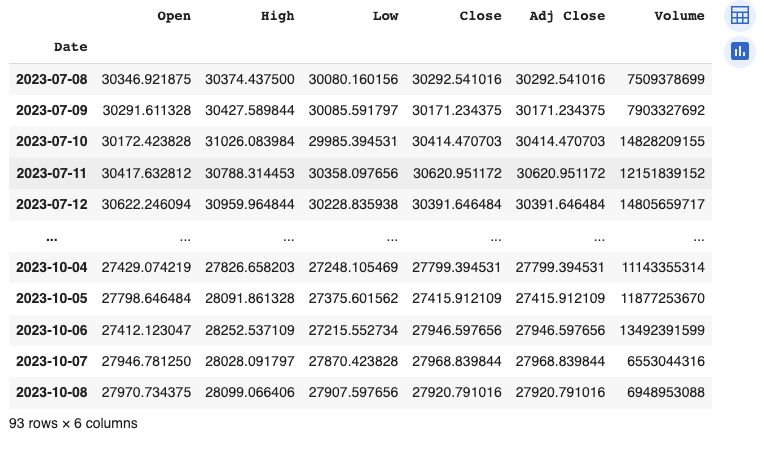
首先,我導入近期3個月每天平均Closing價的數據。
#1m, 2m, 5m, 15m, 30m, 60m, 90m, 1h, 1d, 5d, 1wk, 1mo, 3mo
df = yf.download('BTC-USD', period='3mo', interval='1d')
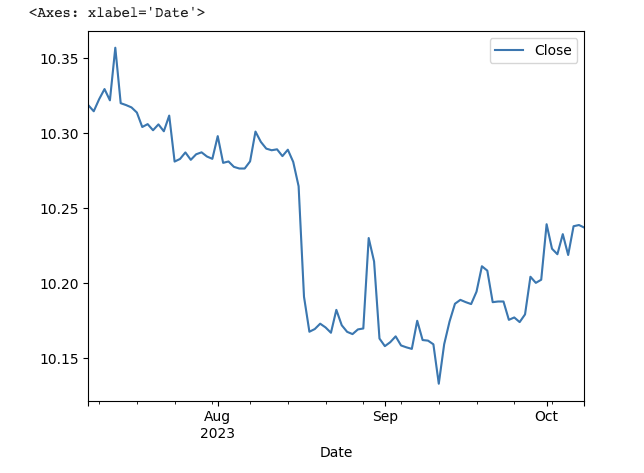
可以先大致看一下線圖走向,上一篇就已經探討過了,BTC波動極大,最近3個月也是。
在這裡我發現DataFrame 只能有Closing 數值,如果用date當x-axis或index的話會搞亂之後要做的一些統計分析。
df2 = df.copy()#備份一下
df2 = df2.reset_index()
df2 = df2[['Close']]#只篩選Closing 價格
df3 = np.log(df[['Close']])
df3.plot()
由於我只有93天的數據, 我決定把前面的63天變成training set 然後用最近期的30天當validation。
#Create a training and testing set
msk = (df2.index < len(df2)-30)
df_train = df2[msk].copy()
df_test = df2[~msk].copy()
然後,用statsmodels module 就可以算出ACF & PACF。
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
acf_original = plot_acf(df_train)
pacf_original = plot_pacf(df_train)
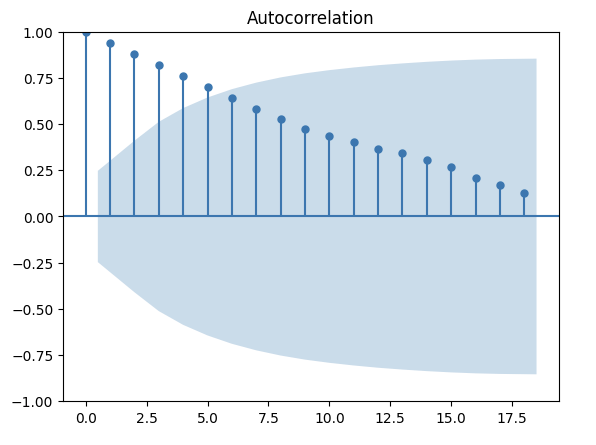
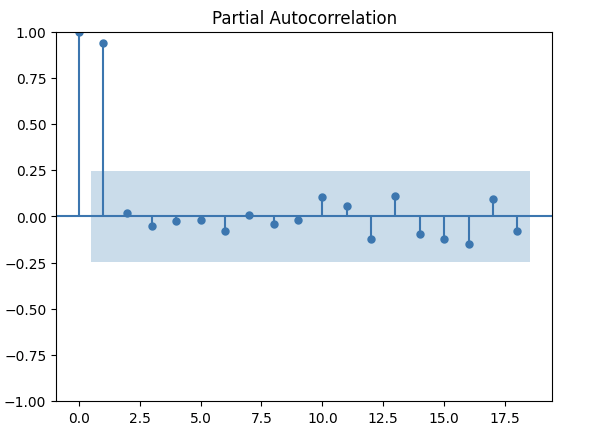
上圖ACF顯示滯後相關性高且在lag 5之後就tail off。大至上呈現了線性衰減的弧度。
PACF在Lag1之後有一個波度/尖峰然後就不見了。
以上的圖表都顯示這數據是非穩定的(non-stationary)。
這時也可以用ADF Test 來做第二確認。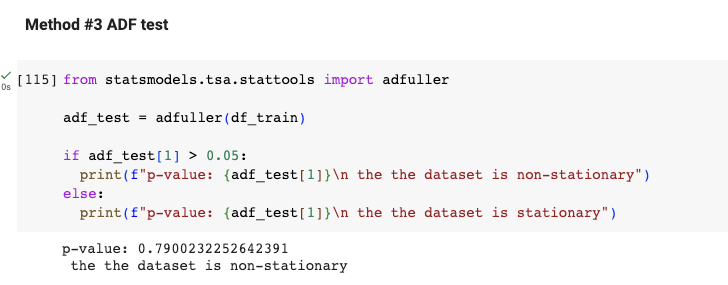
如上圖,如果p-value大於0.05,那這數據就是非穩定的。
**step 2: 用differencing 算出 d **
在數據是非穩定時 可以用differencing 來算出d的指數。
# Find the difference between the values for each row and the values from the previous row:
df_train_diff = df_train.diff().dropna() #applying differencing 1st time
second_diff = df_train_diff.diff().dropna() # applying difference 2nd time
third_diff = second_diff.diff().dropna() # applying difference 3rd time
adf_test_diff1 = adfuller(df_train_diff)
adf_test_diff2 = adfuller(second_diff)
adf_test_diff3 = adfuller(third_diff)
print(f"p-value of 1st difference: {adf_test_diff1[1]}\np-value of 2nd difference: {adf_test_diff2[1]}\np-value of 3rd difference: {adf_test_diff3[1]}")

可以看到我做了三層的differencing。而p-value卻沒有比原來更好,如此可以判定d=0。
我們在一章節繼續討論。
對 dbt 或 data 有興趣?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加
Ref:
https://levelup.gitconnected.com/20-pandas-functions-for-80-of-your-data-science-tasks-b610c8bfe63c

